时间:2024-04-23来源:组合机床与自动化加工技术 作者:彭康等
为了保证滚刀加工质量的一致性,缩短滚刀工艺文件的制定周期,在对滚刀的粗加工工艺进行研究后,采用机器学习方法,将滚刀的几何特征参数作为反向传播(BP)神经网络的输入变量,滚刀粗加工中每个工序的工艺参数作为输出结果,对滚刀粗加工过程中每个工序的工艺参数进行预测。针对传统 BP 神经网络最速下降法收敛速度慢的问题,在研究了“锯齿现象”产生的原因后,提出了一种“修正下降方向”的反向传播神经网络算法。仿真结果说明,与传统 BP 神经网络相比,同等条件下,改进的 BP 神经网络收敛速度加快,预测结果可靠。
滚刀作为齿轮加工中应用最为广泛的一种复杂加工刀具,具有较大的市场需求。由于齿轮零件的品种多变,滚刀生产为小批量、多品种、定制化生产。每一批滚刀需要一套对应加工工艺文件,加之滚刀生产周期缩短,导致工艺人员工作量骤增,影响了企业的生产效率和经济效益。
零件加工工艺文件制定主要分为工序决策和工艺参数决策,引入人工智能技术实现决策是当前学界的研究主流。付晓东利用专家系统结合 BP 神经网络对轴类零件加工工序进行决策,徐昌鸿、金俊生等利用遗传算法、蚁群算法等智能算法对零件加工工序进行决策;针对工艺参数决策,RAJA 等曾基于加工 时长和加工成本对切削用量进行决策,通过加工时长、加工成本两个目标与切削三要素的函数关系建立多目标优化模型,对切削用量进行决策、优化,LIN 等考虑碳排放的问题,将加工时产生的碳排放量作为目标结合加工时长、加工成本目标对切削用量进行决策,有效地降低了加工时长、加工成本和加工碳排放量。
本文针对滚刀的粗加工工艺进行决策,其粗加工工序相对固定,只需对各工序的切削用量进行决策。因此,研究一种基于滚刀几何特征参数,快速准确地预测其加工工艺参数的数学模型显得非常重要。本文采用人工神经网络(ANN)对“经验性”的滚刀加工工艺参数进行学习,然后,用训练好的模型对新型号滚刀粗加工中各工序下的切削参数进行预测,规范工艺加工参数,减轻工艺制定人员的工作量,提升工艺设计效率,提高加工工件质量的一致性。
一、数据集与模型构建
数据集的建立
本文根据 GB/ T6083⁃2016 推荐的滚刀尺寸,通过查阅相关文献,编制对应滚刀的加工工艺参数,经某刀具厂工艺人员审核修改后,供反向传播人工神经网络(BP⁃ANN)训练测试使用。数据集输入的几何特征参数包括关键特征参数和辅助决策特征参数共18 个。其中关键特征参数6 个,参考 GB/ T6083⁃2016 给定;辅助决策特征参数12 个,通过关键特征参数推理计算得到,如表1 所示。

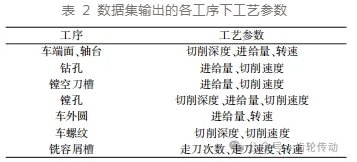
本文基于滚刀车铣复合加工机床,滚刀粗加工的加工工序为:车端面、轴台,钻孔,镗空刀槽,镗孔,车外圆,车螺纹,铣容屑槽。由于滚刀铲齿形的特殊性,滚刀车铣复合加工机床未包含铲车工序。数据集的输出参数为每个工序的切削三要素—切削速度、进给量、背吃刀量。
为了和生产车间的表达方式一致,车端面、轴台,车外圆和铣容屑槽工序的切削速度均用主轴转速表示;钻孔的切削深度为钻头半径,为已知量,无需决策;镗削空刀槽由一刀镗削完成,其镗削深度为设计值,无需决策;由于毛坯直径根据滚刀成品外径通过公式计算得到,在车外圆时一刀车削完成,因此车外圆的切削深度为已知量,无需决策;车螺纹时根据螺纹螺距、头数参数,给定切削速度可以计算得到进给量,车螺纹进给量不再决策。最终确定数据集输出需要预测的工艺加工参数共 17 个,如表 2 所示。
数据集共有 70 条滚刀加工工艺数据,将 70 条数据按照 75% 、25% 的比例圆整后随机抽取、划分出样本集,分别为训练样本和测试样本,即 53 条数据用于试验开发适于本文的 ANN 模型,17 条数据用于测试已形成 ANN 模型的性能。
由于模型输入、输出的参数属性不同、大小迥异,为保证网络在训练过程中保持在一定范围内,测试时得到良好的加工工艺参数预测效果,应当对网络的输入、输出做归一化处理,输入变量的归一化值 pk 由式(1)确定:
式中,pk 为归一化的第 k 个输入值,即工艺数据归一化后的第 k 个几何特征参数;xik为未归一化的第 i 条数据的第 k 个几何特征参数值; ![]() 为未归一化的第 k 个 几何特征参数均值;σ(xk)为未归一化的第 k 个几何特征参数的标准差值。
为未归一化的第 k 个 几何特征参数均值;σ(xk)为未归一化的第 k 个几何特征参数的标准差值。
对理想输出变量 tk 作类似预处理:
式中,tk 为归一化的第 k 个理想输出值,即工艺数据归一化后的第 k 个工艺参数;tik为未归一化的第 i 条数据的第 k 个工艺参数值; ![]() 为未归一化的第 k 个工艺参数均值;σ(tk)为未归一化的第 k 个工艺参数的标准差值。
为未归一化的第 k 个工艺参数均值;σ(tk)为未归一化的第 k 个工艺参数的标准差值。
BP 神经网络模型构建
BP 神经网络(BP⁃ANN)在函数逼近、分类等问题中有着广泛的应用,本文利用 MATLAB 构建上述 BP⁃ ANN 模型。构建的 BP⁃ANN 结构包括输入层、隐藏层和输出层,其中输入层与输出层神经元的个数是确定的,即前文所述 18 个输入值和 17 个输出值;第一层为输入层,输入 18 个几何特征参数;隐藏层的激活函数采用 logsig 函数作非线性的映射;输出层的激活函数使用 pureline 函数,输出 17 个工艺参数;以均方误差作为性能指标,如式(3)所示;训练样本、测试样本均作并行处理,输出数据的权值、偏置调整量作累加求和取均值计算,结果作为该样本该次迭代计算的权值调整量。

式中,ai 为网络的第 i 个输出值,即归一化的第 i 个工艺参数值;e 为误差;因为是作并行处理,黑体表示向量(矩阵)。
对于一般简单的数据集,单个隐藏层来拟合这些函数来说是最佳的,既保证了拟合效果,且减小了过拟合的风险。在网络训练过程中,网络结构对预测效果有十分重要的影响,试用不同的隐含层,根据平均相对误差来选择适合的模型。故本文采用一个隐藏层,而隐藏层神经元的数量通过试用不同的隐藏层神经元个数得到输出值的均方误差值大小来确定,BP⁃ ANN 结构如图 1 所示。
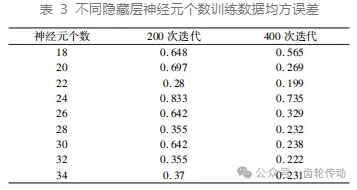
经过 MATLAB 仿真,不同结构神经网络的训练均方误差如表 3 所示。不同的隐藏层神经元个数在 200 次迭代时,输出结果的均方误差值均收敛。取 200 次迭代均方误差值结果和 400 次迭代均方误差值作为确定隐藏层神经元个数的参考,可见:隐藏层神经元个数 为 22 个时,均方误差值明显优于其它结构,故确定 BP⁃ANN 结构为 18⁃22⁃17。
二、反向传播神经网络优化算法
传统反向传播神经网络的输入经过权值、偏置、激活函数前向传播后可以计算得到性能指标,本文即式(3)所示的均方误差;为了使得性能指标值在下一次前向传播减小,让性能指标分别对每个权值、偏置求偏导,得到性能指标关于权值、偏置的梯度,取负梯度方向修改权值、偏置,得到下一次前向传播的新的权值矩阵和偏置向量,其中取负梯度方向的做法就是最速下降法。
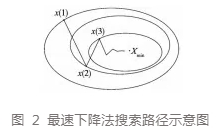
由于应用领域技术的快速发展,BP 神经网络算法也出现了一些弊端,其中最为突出的是在学习过程中误差收敛速度过慢的问题。实践证明最速下降法会存在“锯齿现象” ,如图 2 所示。在性能指标函数构成的 n 维超平面中,已知点的最速下降方向并不一定是直指全局最优点,其仅仅是已知点局部的最速下降方向,所以其搜索路径呈现锯齿状,导致收敛速度变慢。
共轭梯度法通过已知点处的梯度构造一组共轭方向,并沿这组方向进行搜索,求出目标函数的极小值点,这种方法具有二次终止性,能够加快目标函数的收敛速度,减小“锯齿现象”对收敛速度的影响。然而对于一般目标函数,共轭梯度法需要求解目标函数的 Hesse 矩阵,本文 BP⁃ANN 第二层的激活函数为 pureline 函数,其二阶导数为 0,无法进行权值矩阵和偏置向量的更新。
观察图 2,等值线任意一点 x(k)处的梯度为该点的法向量;且点 x(k)在远离极值点时,该点的邻域内任一点 xr(k)的梯度与点 x(k)处的梯度方向大致相同,如图 3 所示,图中虚线圆为 x(k)的邻域,此时点 x(k)的邻域不包含极值点。在迭代点邻域内取随机点 xr(k),将两点处的梯度方向 dk、dkr合成为 dkn ,使新的下降方向梯度增大,能够增大搜索步长,加快在远离极值点时的收敛速度。
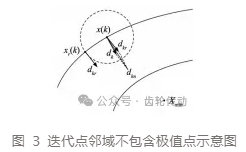
在接近极值点时,如图 4 所示,点 x( k)的邻域包含极值点。此时,点 x(k)邻域内任一点 xr( k)的梯度与点 x(k)处的梯度方向的夹角是随机的。对于夹角大于 90° 的情况即图 4,新的合成下降方向 dkn梯度的范数会小于 dk,起到缩小搜索步长的作用,避免搜索路径越过极值点,而在极值点附近振荡;夹角小于 90°时,新的下降方向还是起到一个加速的作用,但是在搜索后期应当避免。
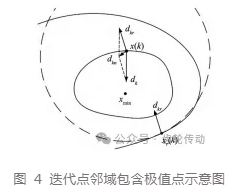
通过对搜索路径的分析,本文 BP⁃ANN 反向传播的下降方向基于迭代点的梯度,在迭代点的邻域中随机取一点获得该随机点的梯度,将两者合成取反方向,如式(4)所示,使邻域内随机点的梯度去“修正”已知点的最速下降方向,以加快收敛速度,避免了计算目标函数的高阶导数。
式中,d(x(k))为第 k 次迭代点处修改后的下降方向;▽F(x(k))为第 k 次迭代点处梯度;▽F(xr( k))为第 k 次迭代点的邻域随机点处梯度。
实验发现:当到了迭代后期,迭代点靠近极值时,如果依旧使用邻域随机点的梯度去合成最速下降方向,可能会使搜索路径偏离极小点而围绕极小值点振荡,使目标函数值一直处于一个范围值内,无法逼近极小值。如前文分析,在接近极值点时,搜索路径会出现围绕极值点振荡的现象,故本文 BP⁃ANN 仅在迭代前期使用邻域随机点梯度进行下降方向的修正,以加快收敛速度,搜索后期不再“修正”下降方向,直接使用最速下降方向逼近极小值点。表 4 为两种算法前 9 次迭代计算的均方误差值。
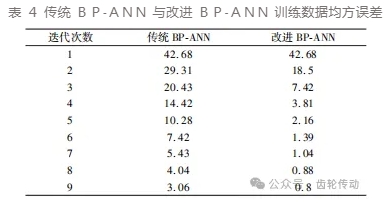
传统 BP⁃ANN 在 1066 次迭代后均方误差达到 0. 1,改进的 BP⁃ANN 在 544 次迭代后均方误差达到 0. 1。两种算法的均方误差值在同时达到 0.1 的条件下,改进后的 BP⁃ANN 相较传统 BP⁃ANN 减小了 522 次迭代计算。可见改进后的 BP⁃ANN 算法较传统 BP⁃ ANN 算法,在迭代前期其收敛速度有一定提升。
三、模型的检验与评价
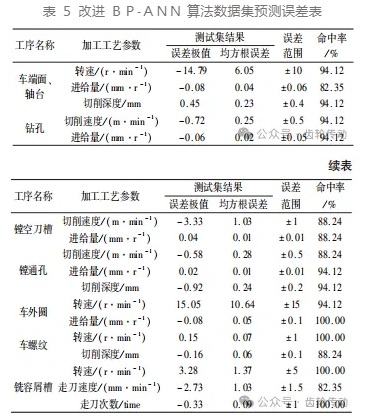
本文采用 MATLAB 编写算法,对修改的 BP⁃ANN 的算法进行验证,训练集、测试集分别按照数据集的 75% 和 25% 圆整划分。本测试对滚刀粗加工过程中的加工参数进行预测,采用误差极值和均方根误差(RMSE)评价与检测模型预测效果,预测结果如表 5 所示,如第一个车端面、轴台工序中的转速预测结果,测试集中转速值范围在 700 r/ min ~ 900 r/ min。本文模型对其转速的预测值中,预测值的最大误差为 - 14.79 r/ min,预测值的均方根误差为 6.05 r/ min,在允许上下浮动 10 r/ min 的条件下,预测值的命中率为 94.12%,其余 16 个工艺参数的预测结果如表 5 所示。
四、结论
为能较准确地预测滚刀粗加工 7 个工序的 17 个切削参数,本文构建了基于 BP 神经网络的工艺参数预测模型,并在传统 BP⁃ANN 的基础上,建立基于 BP⁃ ANN 的改进预测模型,运用本文提出的改进 BP⁃ANN 对滚刀粗加工工艺参数建立预测模型,进行参数预测和模型性能检验,可得出以下结论:
(1)在本文的应用背景下,仿真实验证明采用改进 BP⁃ANN 算法能加快迭代前期的收敛速度。在性能指标同时到达 0.1 的条件下,改进 BP⁃ANN 算法收敛速度达到传统 BP⁃ANN 的近两倍,具有收敛速度较快的优势。
(2)本文中经训练集训练的神经网络,其预测结果在许可范围内可较为准确地得到滚刀加工中各工序对应工艺参数的预测值,命中率均在 80% 以上,证明了本文所提方法的可行性。
参考文献略.
下一篇:热塑性塑料齿轮的设计与制造
免责声明:凡注明(来源:齿轮头条网)的所有文字、图片、音视和视频文件,版权均为齿轮头条网(www.geartoutiao.com)独家所有,如需转载请与本网联系。任何机构或个人转载使用时须注明来源“齿轮头条网”,违反者本网将追究其法律责任。本网转载并注明其他来源的稿件,均来自互联网或业内投稿人士,版权属于原版权人。转载请保留稿件来源及作者,禁止擅自篡改,违者自负版权法律责任。
相关资讯
网站简介 | 会员服务 | 联系方式 | 帮助信息 | 版权信息 | 网站地图 | 友情链接 | 法律支持
齿轮头条网--齿轮与先进制造业的“全媒体”综合资讯平台
 客服热线:010-88438553
销售热线:18611505795/18611500535/18611505587
新闻热线:18611505788
客服热线:010-88438553
销售热线:18611505795/18611500535/18611505587
新闻热线:18611505788
鑫格尔传媒(北京)有限公司 geartoutiao.com Copyright ©2020-2025,All Rights Reserved 版权所有 不良信息举报中心 | 京ICP备 18007354号-2 | 京公网安备 11011202002671号





 网站客服
网站客服